[패스트캠퍼스 백엔드 부트캠프 3기] 6주차
1. 기본 개념
PK : 데이터의 코드화 --> 변경에 유리
FK : 다른 테이블의 PK ( 테이블간 관계 표현)
ROW : 객체 (iv 집합)
COLUMN : 객체 배열
Fk 없으면 관계를 알 수 없다
DB ~= HashMap(객체배열) + TreeSet
Tree와 hashmap 의 장점을 연결 (11장이 중요한 이유)
RDB는 Map과 비슷한 형태이다. Map : key 중복 x, 순서 x , 객체 배열 형태
SQL : RDB에게 질문하는 언어
DB(데이터의 그룹화, 2차원 배열 여러개): 고정형 DB -----중복 제거: 테이블 쪼개서 관계 형성------> RDB (그룹 + 관계) : 고정형 DB ----보완----> NoSQL (유연, 비정형 DB)
테이블 쪼개면 관계가 생긴다. 왜? 원래 하나였으니까
* 디자인패턴
* 분리 : 변하는것과 변하지 않는것 나누기 (분리대상 : 변하는것)
변하지 않는것 : 템플릿 -- 건들지 않기
바꾸고 싶으면 상속해서 쓰거나 포함해서 쓰라는 것이 기본 목적
방법 3개
1. Template method :분리 후 상속으로 결합 ------- 상속이므로 자손에 기능추가 가능
2. Strategy : 분리 후 포함으로 결합 ---- 포함이므로 기능추가 가능
3. Bridge : 분리 후 상속과 포함으로 결합
== OCP : 상속엔 open(가능하다), 변경엔 close(불가능)
* Singleton, FlyWeight,Prototype,TemplateMethod,Bridge,Iterator,Decorator,Future(비동기 -- 기다리기 싫어서 빈박스 주기)
2. 날짜 다루기 -- 직접 형변환하기

비추천 : 자동형변환
추천 : 직접 목적에 맞게 형변환하기
* 날짜에서 이번달 마지막 날 구하기
== 다음달 1일에서 -1 하기
3. 평균 구할때 Null 처리 방법

4. NON - EQUI 조인은 누적계산에 유리 (적합)


5. JOIN( EQUJOIN)이 where절에 = 연산자로 사용한다.
Oracle 설치 오류로
Docker + SQLdeveloper 사용함
실습
(틀린 부분 있을 가능성 有)
1) Group by를 사용하는 이유 == 그룹함수 사용하기 위해서
일단 묶어 놓아야 그룹에 적용할 수 있기 때문에 사용한다.
SQL문에서 GROUP BY 옆에 그룹함수를 사용하지 못하는 이유가,
그룹함수로 묶는게 아닌 다른 컬럼으로 묶어서 그룹함수를 적용하는 것이기 때문이다.
그리고 그룹함수는 where절에 사용할 수 없다. (왜 ? WHERE 절은 모든 레코드에 대해서 조건을 적용한다. HAVING절은 GROUP BY절을 통해 만들어진 GROUP들에만 조건을 적용한다. 그래서 WHERE 조건절에는 집계함수를 쓸 수 없는것이다. ) *인용1
예시를 들어서 설명해보면


이렇게 그룹을 만들어 놓고

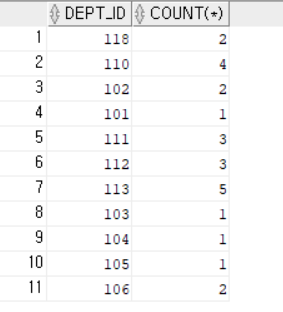
그다음에 함수를 적용하는 것이다
2) OUTER JOIN의 +의 위치 : 데이터가 더 작은쪽에 보통 + 를 붙인다.
+의 위치에 따른 차이를 두가지 예시로 비교해보면
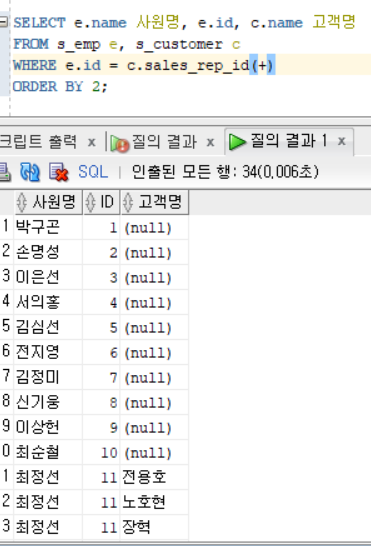
이 예제를 JOIN으로 하면 E가 가진 직원 번호와 C가 가진 고객 번호가 일치하는 것만 출력된다.
OUTER JOIN은 일치 하지 않는것까지 함께 볼 수 있게 한다. 그러면 고객또는 직원이 배정되지 않거나 일치하지 않는 것까지 볼 수 있다.
JOIN할 데이터가 더 작은쪽에 (+) 연산자를 붙인다고 했다.
그러면 첫번째 사진은 c에 +를 붙였으므로 E 쪽이 더 큰 데이터이다.
그러면 C는 일치하는 부분만 나오고 , E는 일치하지 않는 부분까지 나오므로
고객이 배정되지 않은 직원들도 나오게 된다.
--> 놀고 있는 직원 찾기
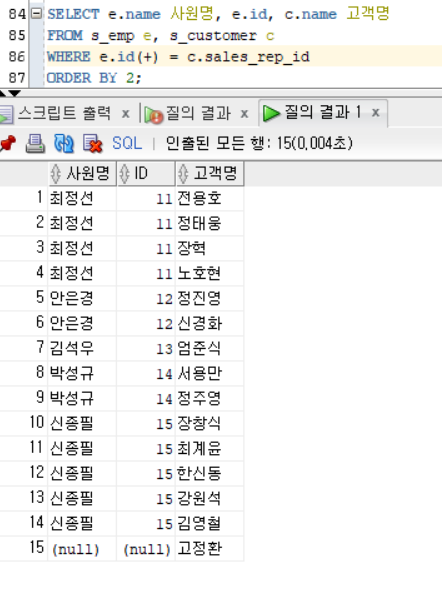
두번째 사진은 E에 +를 붙였으므로 C쪽이 더 큰 데이터이다.
그러면 E는 일치하는 부분만 나오고, C는 일치하지 않는 부분까지 나오므로
직원이 배정되지 않은 고객도 나오게 된다
--> 신규 고객 찾기
3) SELF JOIN은 언제 사용하는지 잘 모르겠다. --아직 이해 못함
4)
*SET 연산자 : 쿼리의 집합
UNION : 합집합
UNION ALL : 공통 고려 없이 이어 붙이기 (합집합+ 교집합)
INTERSECT : 교집합
MINUS : 합집합
* UNION보다 UNION ALL 을 사용하는 것이 유리하다
이유 : 공통부분을 찾아야 함 --> 만약 겹치는것이 없으면 굳이 찾으려고 헛수고하는셈
SubQUERY
1. SINGLE-ROW SubQUERY
:전달되는 서브쿼리가 값인 경우 / 단일행연산자 사용
예시
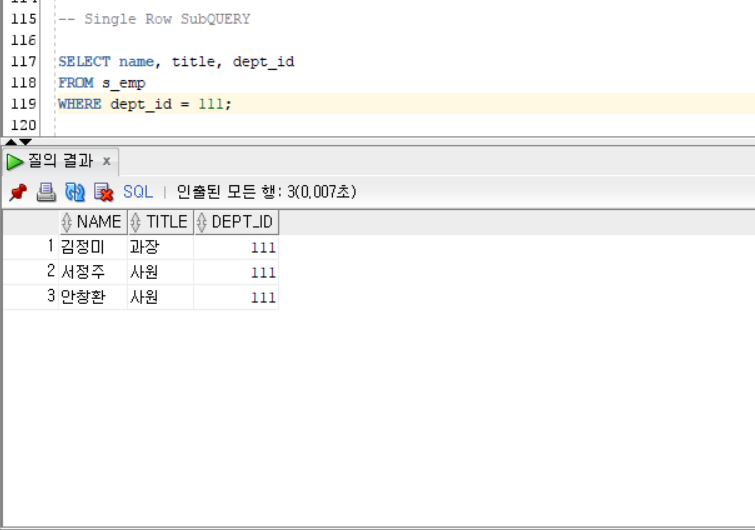
이 예시의 '111' 부분을 서브쿼리로 바꾸면 single row 서브쿼리가 된다

2. MULTI -ROW SubQUERY
이 경우는 값이 1개가 아닌 여러개인 경우 이다.
IN이나 NOT IN같은 다중 행 연산자를 사용한다.

예시를 보면, 첫번째 쿼리와 두번째 쿼리가 완전히 일치하는 쿼리임을 알 수 있다.
3 . MULTI - COLUMN SubQUERY(Pair - wise)
위의 서브쿼리들은 한 컬럼을 가지고 비교했지만
MULTI -COLUMN 서브쿼리는 여러 컬럼을 동시에 비교하는 것이다


4 .From 절에서의 SubQuery (INLINE VIEW)

FROM 절에 있는 ( ) 괄호가 직접 새로 테이블을 만들어 넣었다고 생각하면 된다
이유 : 한 테이블에 데이터의 양이 많은 경우에 from 절에 테이블을 그냥 넣으면 효율이 좋지 않음
FROM S_EMP , S_DEPT가 아닌

새로 만든( 진짜 만들어진건 아님) 이 테이블을 S_EMP2라고 하면
SELECT e.name, e.title, d.name
FROM s_emp2 e, s_dept d
WHERE e.dept_id = d.id;
와 동일해진다
5. HAVING 예제
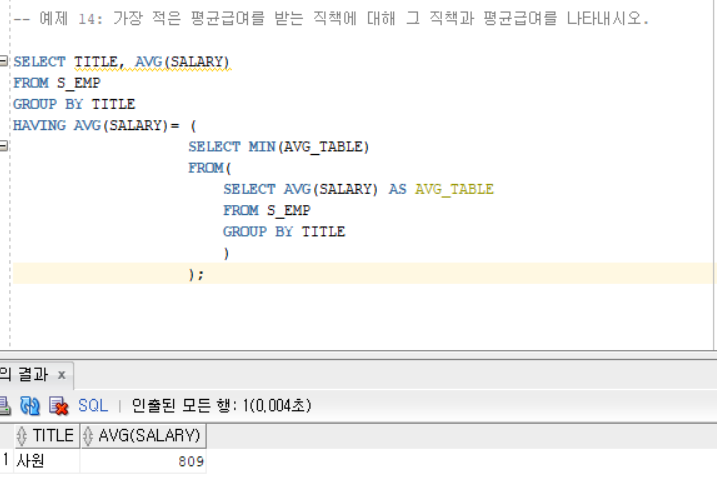
HAVING 에 저렇게 값이 아닌,, FROM 서브쿼리를 활용한 테이블을 넣은 이유는
평균급여를 직책별로 나눠서 계산하면 AVG (SALARY ) 가 여러개 나오기 때문이다. 그래서
AVG_TABLE을 새로 만들었는데
AVG_TABLE은 밑의 왼쪽 사진을 오른쪽으로 만든 테이블이라고 생각하면 쉽다
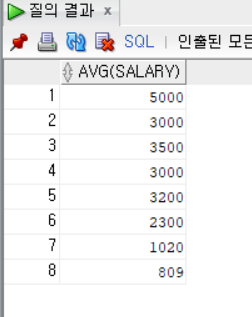
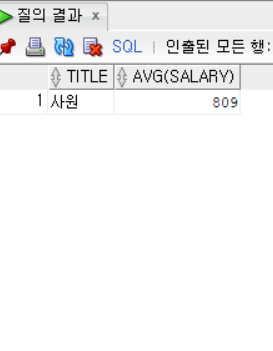
그래야 HAVING절에서 직책의 평균급여를 MIN(AVG(평균급여) 와 비교할 수 있다.
6. CREATE 절에서의 SUBQUERY
이해 못함 ---

7. DML문에서의 SUBQUERY

* 아직 어려워서 이글은 정리가 좀 필요하다.
참고 1: 커밋 관련 사용법
https://blog.naver.com/regenesis90/222213840145
[오라클/SQL] COMMIT, ROLLBACK : 커밋(작업 확정), 롤백(작업 취소) - 트랜잭션 제어 명령어
트랜잭션(Transaction)을 제어하는 명령어로는 다음의 세 가지가 있습니다. * 본 포스팅에서는 COMMI...
blog.naver.com
참고 2 : SQL Developer에서 검색 결과 엑셀로 내보내기
[Oracle] SQL Developer에서 검색 결과 Excel로 내보내기
1. 검색 된 결과에서 오른 쪽 마우스를 클릭해서, "익스포트(E)"를 선택 합니다. 2. "형식(F)"을 아래와 같이 선택해 줍니다 3. "찾아보기(R)"을 눌러서, 저장 경로와 파일명을 설정 한 후, "저장" 버튼
overit.tistory.com
참고 3 : SQL Developer로 내보내기
[Oracle] SQL Developer로 내보내기
1. Oracle에서 SQL문으로 뽑아내기 SQL Developer의 도구>데이터베이스 익스포트> insert문, excel, delimited 형식으로 내보내기 가능 1) insert문으로 뽑으면 sql창에서 @'절대경로\파일명.sql'로 실행가능 -> 데
ssunws.tistory.com